What’s the most powerful artificial intelligence model at any given moment? Check the leaderboards.
Community-built rankings of AI models posted publicly online have surged in popularity in recent months, offering a real-time look at the ongoing battle among major tech companies for AI supremacy.
Each leaderboard tracks which AI models are the most advanced based on their ability to complete certain tasks. An AI model at its root is the set of mathematical equations wrapped in code designed to accomplish a particular goal.
Some newer entrants, such as Google’s Gemini (formerly Bard) and Mistral-Medium from the Paris-based startup Mistral AI, have stirred excitement in the AI community and jockeyed for spots near the top of the rankings.
OpenAI’s GPT-4, however, continues to dominate.
“People care about the state of the art,” said Ying Sheng, a co-creator of one such leaderboard, Chatbot Arena, and a doctoral student in computer science at Stanford University. “I think people actually would more like to see that the leaderboards are changing. That means the game is still there and there are still more improvements to be made.”
The rankings are based on tests that determine what AI models are generally capable of, as well as which model might be most competent for a specific use, like speech recognition. The tests, also sometimes called benchmarks, measure AI performance on such metrics as how human AI audio sounds or how human an AI chatbot response appears.
The evolution of such tests is also important as AI continues to advance.
“The benchmarks aren’t perfect, but as of right now, that’s kind of the only way we have to evaluate the system,” said Vanessa Parli, the director of research at Stanford’s Institute of Human-Centered Artificial Intelligence.
The institute produces Stanford’s AI Index, an annual report that tracks the technical performance of AI models across various metrics over time. Last year’s report looked at 50 benchmarks but included only 20, Parli said, and this year’s will again shave off some older benchmarks to highlight newer, more comprehensive ones.
The leaderboards also offer a glimpse at just how many models are in development. The Open LLM (large language model) Leaderboard built by Hugging Face, an open-source machine learning platform, had evaluated and ranked more than 4,200 models as of early February, all submitted by its community members.
The models are tracked on seven key benchmarks that aim to assess a variety of capabilities, such as reading comprehension and mathematical problem-solving. The evaluations include quizzing the models on grade-school math and science questions, testing their commonsense reasoning and measuring their propensity to repeat misinformation. Some tests offer multiple-choice answers, while others ask models to generate their own answers based on prompts.
Visitors can see how each model performs on specific benchmarks, as well as what its average score is overall. No model has yet achieved a perfect score of 100 points on any benchmark. Smaug-72B, a new AI model created by the San Francisco-based startup Abacus.AI, recently became the first to break past an average score of 80.
Many of the LLMs are already surpassing the human baseline level of performance on such tests, indicating what researchers call “saturation.” Thomas Wolf, a co-founder and the chief science officer of Hugging Face, said that usually happens when models improve their capabilities to the point where they outgrow specific benchmark tests — much like when a student moves from middle school to high school — or when models have memorized how to answer certain test questions, a concept called “overfitting.”
When that happens, models do well on previously performed tasks but struggle in new situations or on variations of the old task.
“Saturation does not mean that we are getting ‘better than humans’ overall,” Wolf wrote in an email. “It means that on specific benchmarks, models have now reached a point where the current benchmarks are not evaluating their capabilities correctly, so we need to design new ones.”
Some benchmarks have been around for years, and it becomes easy for developers of new LLMs to train their models on those test sets to guarantee high scores upon release. Chatbot Arena, a leaderboard founded by an intercollegiate open research group called the Large Model Systems Organization, aims to combat that by using human input to evaluate AI models.
Parli said that is also one way researchers hope to get creative in how they test language models: by judging them more holistically, rather than by looking at one metric at a time.
“Especially because we’re seeing more traditional benchmarks get saturated, bringing in human evaluation lets us get at certain aspects that computers and more code-based evaluations cannot,” she said.
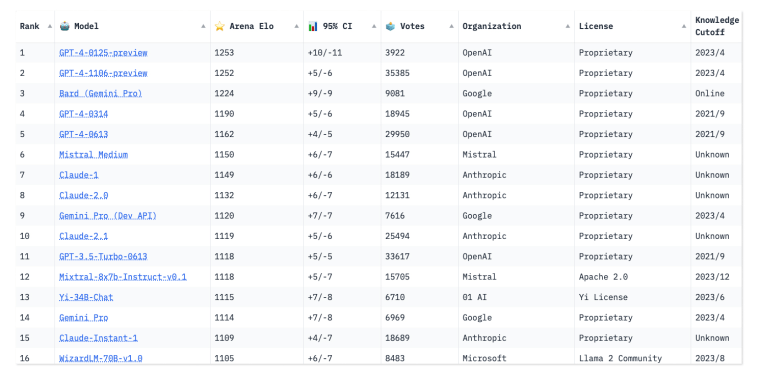
Chatbot Arena allows visitors to ask any question they want to two anonymous AI models and then vote on which chatbot gives the better response.
Its leaderboard ranks around 60 models based on more than 300,000 human votes so far. Traffic to the site has increased so much since the rankings launched less than a year ago that the Arena is now getting thousands of votes per day, according to its creators, and the platform is receiving so many requests to add new models that it cannot accommodate them all.
Chatbot Arena co-creator Wei-Lin Chiang, a doctoral student in computer science at the University of California-Berkeley, said the team conducted studies that showed crowdsourced votes produced results nearly as high-quality as if they had hired human experts to test the chatbots. There will inevitably be outliers, he said, but the team is working on creating algorithms to detect malicious behavior from anonymous voters.
As useful as benchmarks are, researchers also acknowledge they are not all-encompassing. Even if a model scores well on reasoning benchmarks, it may still underperform when it comes to specific use cases like analyzing legal documents, wrote Wolf, the Hugging Face co-founder.
That’s why some hobbyists like to conduct “vibe checks” on AI models by observing how they perform in different contexts, he added, thus evaluating how successfully those models manage to engage with users, retain good memory and maintain consistent personalities.
Despite the imperfections of benchmarking, researchers say the tests and leaderboards still encourage innovation among AI developers who must constantly raise the bar to keep up with the latest evaluations.